What I Learned Building Tools for AI Agents #
For the last 10 months, I've been what I call a "markdown monkey": vibecoding my way through building tools. What an adventure, trying to figure out where my designer-brain fits in this AI world.

I started this year searching for a DSL—something designers, PMs, and developers could share before pixels. Few months in, dialogue replaced artifacts. Intent became the contract. Now I'm landing somewhere stranger: PRs might replace Figma entirely. UI flows as executable specs. Polish as the last step. Rough first, real constraints, iterate where it counts. I'm just getting there through CLI tools and text files.
Tried explaining ideas in English and hoping models turned my intentions ("vibes") into code. They did, until they didn't. After enough failed attempts, enough mix-bag codebases I couldn't maintain, I realized: if I can't hold complexity in my head, write it down.
I started keeping EVERYTHING in markdown files. Design decisions, draft plans, why I changed my mind. I labeled folders, signposted things. If I could grep my way through my own mess to remember what I decided, so could models.
And recently, I was watching Kai Hendry's podcast with Vincent, and one bit stuck with me. It's exactly what I've been dealing with:
"How many times have I checked out a codebase where things are scattered around? It's got to have a makefile at the root, all the tools there. But that repo hygiene is tech debt that never gets addressed, and these things trip over AI all the time." (43:25)
The pattern I kept seeing: agents work better when they can discover what they need. Repo structure, command options, file formats. If an agent can see the shape of the system, it doesn't need much coaching.
Kai also references Theo's rant: "too much MCP, you're going to have a bad time." Context rot is real. MCP servers can dump 50+ tool definitions into context upfront. Anthropic added Tool Search to fix this. I built cc-toys to do the same: switch MCP profiles per session, not load everything. CLI tools never had the problem. Run --help, see the options, done.
Immediate field notes: Beads worked because it's both file-based and agent-first. Vercel's agent-browser outperformed the browser MCPs I tested (claude-in-chrome, chrome-devtools, playwright-mcp, browsermcp.io). Both are CLI tools with good self-documentation. My markdown files work because agents can grep through labeled folders.
Here's what pushed me toward CLI-first.
Joining the Framework Club #
Three things influenced this. And yeah, I still ended up building my own.
GSD (Get Shit Done) #
GSD showed me something I'd never seen: plans as executable documents. Not "here's what I hope to do," but "here's the spec, go run it." That changed how I think about solo workflows.
The numbered folders .planning/01, .planning/02 proved that agents can navigate if you give them a path. The /slashcommands pattern worked because models don't need instructions, they need structure they can discover.
Where it didn't fit my workflow:
- I'm juggling five things at once. GSD is great for a straight line; my work isn't.
- I wanted the state machine to be obvious, not something the model infers.
- And I wanted to see progress while it's happening, not just "done / not done."
But GSD convinced me: if the plan is structured enough to execute, agents can actually follow it. Tiller and later Ore came from that. I just needed it to work with my "five things on fire" workflow.
Spec Kit #
Spec Kit taught me about contracts: testable promises about behavior, binding decisions made in docs first. But I kept getting lost between "what the spec says" and "what the repo looks like right now." Too often I was debugging the process instead of the work.
Both had a similar friction point: slash commands in sequences I could never remember. Constant trips back to the docs to figure out "what's next?" The cognitive overhead got old fast.
Beads #
Beads is a CLI-based issue tracker designed for agents: dependency graphs, multi-phase workflows, human gates, all through files. The README says it "replaces messy markdown plans with a dependency-aware graph."
I did the opposite: messy markdown WITH dependency graphs. Took their ready and status commands though. But the complexity bounced me. Chemistry terms like pour/wisp/squash, TOML formulas, multi-phase everything. I needed something I could hold in my head today, not after a weekend of study.
So I built simpler versions:
- Explicit state machines: draft → approved → ready → verifying
- Filesystem-based state tracking through folder naming conventions (
.locksuffix, numbered folders, initiative/phase/plan hierarchy) - CLI commands for every transition
Did I reinvent a wheel? Almost certainly. Yegge's formulas have human gates plus GitHub Actions checks, pull request gates, timers, way more sophisticated. But I needed a wheel I could steer today while I wrapped my head around the basics.
Sticking to my lane for now. Might circle back when I can dedicate time to understanding molecules properly.
Beads tells you what's blocked. What I was after was a map of the journey: which phase I'm in, what gate I'm stuck at, and what "next" looks like. Git shows history. Beads shows dependency. I wanted something that shows intent and reality side-by-side, without doing gymnastics in commit logs.
Tiller: Teaching Agents What to Do Next #
Self-Guiding CLI with State Machines #
Could an agent drive a CLI using nothing but --help? No special prompt voodoo? What if the CLI showed exactly where you are and what's allowed?
Tiller uses a hierarchical state machine: draft → approved → ready → active → verifying → complete. Every command returns TOON—structured data plus current state:
accept:
spec: specs/0001-feature
initiative: feature-launch
phases_created: 3
plans[3]{ref,run_id,state}:
06.1,run-abc,ready
06.2,run-def,ready
06.3,run-ghi,ready
agent_hint: "Plans are ready. tiller activate 06.1"What just happened, where you are, what's allowed. Agents query tiller status --json, see available transitions, proceed autonomously. Follows beads' bd ready pattern: ask "what's unblocked?" and get a deterministic answer.
This is what I kept tripping on with GSD and Spec Kit: I'd forget the sequence. With Tiller, the CLI tells the agent its next move. Ryan Singer's UI flow shorthand ("what to do, what users see, what will they do next") adapted for CLI agents instead of button-clicking humans. I've explored this in posts about sketching states before screens and balancing exhaustive state modeling with clear narrative paths.
Ore: When Agents Built Their Own Tool #
After using tiller for a while, I realized I needed something more deterministic. I ping-ponged between ChatGPT and Gemini, pasting their responses back and forth, explaining in my vibes mode. They built on each other's ideas in ways honestly above my paygrade. But I gave it a shot:
Asked Opus to extract the ChatGPT-Gemini transcript into a half-baked spec
Ran a ralph loop, a simple bash while loop spawning one agent over and over with fresh context each time
Ralph is Geoffrey Huntley's technique, in its purest form:
while :; do cat PROMPT.md | claude-code ; done. Not multi-agent execution, just one agent iterating indefinitely. I used Clayton Farr's ralph-playbook implementation, not Anthropic's ralph-wiggum plugin.Watched them read transcripts, craft specs, create
IMPLEMENTATION_PLAN.mdInjected
<agent-instructions>tags and police car lights 🚨 while they were running, hoping they'd pick up the guidance on the next iteration
The counterintuitive surprise: I wanted determinism through structure—finite states I could predict. Ralph showed me a different kind of determinism: autonomous agents looping until they converge on something. Which is better? I still don't know.
The pattern held: they kept expanding autonomously. Specs, implementation plans, phases, architectural decisions. After +15 iterations, they were still going. They landed on their own terminology: ore, smeltry, jail, assay. A whole mining metaphor. Built a CLI I spent a day trying to understand. (Ironic, considering I'd just bounced off beads' chemistry terms. Tiller was steering through nautical waters, ore went mining—agents gonna metaphor.)
I threw it away and started fresh.
Learning from the Throw-Away #
New repo, spawned a "horde of Sonnets" to decode the throw-away code. Used ChatGPT as a sidecar to help make sense of it.
Through the dialogue, I followed the model's preferences and forced them to make "opinionated decisions." I asked them to be the customer/user of the CLI, dogfood it, be relentlessly pragmatic, unix-principled.
I ended up taking their side. They made major changes to tiller's approach:
- Wanted:
ore <verb> <noun> <--flags>— git-like, verb-first - Not:
tiller plan create— noun-first, domain-grouped
I watched them run CLI commands incredibly fast. The state machine behind enforces what commands are allowed/blocked, that's the determinism.
They taught me "everything is a file", using sentinel directories to track state. Their big idea was simple: make state visible. A folder is the truth. If __halted__/ exists, you're halted. If it doesn't, you aren't. And because it's a folder, creating it is atomic: mkdir works or it doesn't.
Sentinel directories can contain metadata files too. Everything is readable by both agents and humans: check status via CLI (ore status --json) or filesystem (ls). No hidden state.
Example flow:
# 1. Draft exists with content
cat plans/01-checkout-flow.draft/PLAN.md | head -n 5
# → ## Checkout Flow Implementation
# → Add payment processing step...
# 2. Human approves
ore approve 01-checkout-flow.draft
# → Renamed to checkout-flow.ore-wer1/
# → Created __approved__/ sentinel
# 3. Agent runs verification (fails)
ore verify checkout-flow.ore-wer1
# → exit code 1
# 4. Agent checks what failed
ore status checkout-flow.ore-wer1 --json
# → { "plan_state": "HALTED", ... }
# OR reads failure reason directly
cat checkout-flow.ore-wer1/__halted__/reason.txt
# → Task failed: npm test exited with code 1
# 5. Agent retries
ore retry checkout-flow.ore-wer1I asked for sidebar ergonomics. State changes needed to be visible in neotree. They gave me directory-based state.
The Infinite Runs Pattern #
So I ended up with an "infinite loop" workflow, very ralph-ish: run → verify → if it fails, stop loudly (__halted__/) → inspect → fix → reset the task → try again. Same plan, better each pass.
The trick is I don't restart the whole plan. I reset one task and take another swing. And since failure becomes a folder in the repo, it's basically sitting right there, hard to ignore.
The NEEDS_UAT gate is a hard stop that prevents auto-continue without human approval, but it doesn't halt, it waits. Agents can query and decide what to do.
Every iteration is auditable via append-only JSONL ledger. You can see exactly what the agent tried, what failed, what it fixed.
Task Dependencies #
I needed dependencies too. Not in a fancy way, more like "don't run B until A is done." So ore keeps a simple dependency graph and can answer the only question the agent keeps asking: what can I do next? That's basically ore ready. If I want to eyeball the shape of the work, ore dag gives me the picture. READY, BLOCKED, RUNNING, PASSED, FAILED, NEEDS_UAT. I mostly care about one thing: what's unblocked right now.
I've noticed the same file-based "task state" idea popping up in a few places, including Anthropic's Tasks API work. I thought I was being original with ore, then I realized I'd just wandered into a neighborhood other people were already building in. Kind of reassuring.
On the same episode, Vincent describes a company's workflow at 45:40 that follows the exact same pattern: Phase 1 is breaking down product requirements into user stories, functional requirements, acceptance criteria. Creating specifications, plans, phases, and tasks. Then in Phase 2, AI becomes the driver because the validation mechanisms are defined.
That's pretty much what I backed into with tiller/ore, just from a naive designer-brain angle.
Tiller is "stick to the plan, don't guess": PLAN.md plus TOON. Ore is "let the agent run, but don't let it redefine done": locks/halts plus NEEDS_UAT. Humans set the bar, agents do the laps.
Where My Approach Diverges #
After about 15 minutes of conversation starting at 57:18, Kai and Vincent land on an aspirational workflow:

The idea: throw away the POC code and regenerate from specs, avoiding undocumented edge cases baked into the initial implementation.
They're talking production infrastructure; I'm a designer stumbling through CI concepts. But the "throw away and rebuild" hit home. I'd just done that with ore, not from methodology but desperation (first version was incomprehensible). Where I went different: kept version two, built infinite improvement loops into it. When verification fails, agents see __halted__/ in the workspace, propose a fix, reset the task, retry. The code evolves in place.
Also: explicit state visibility. GSD and Spec Kit manage state internally. You invoke slash commands and the framework tracks where you are. Mine makes state visible in the filesystem. Folder names, sentinels, file structure. You can see what state you're in by looking at the repo. That visible state shapes the conversation: if a plan is in "verifying" state, that's what we talk about. State isn't managed by the framework, it's discovered in the filesystem.
On Testing (Or My Lack Of It) #
Vincent mentions Kiro in the podcast. They're discussing serious testing—property-based tests with Hypothesis, EARS format, auto-generated tests from specs. I don't really get the theory. What I know from experience: agent-generated code "works on my localhost:3000" ✨ until it spectacularly doesn't. Pre-Opus 4.5 especially, I'd watch code look perfect, then break mysteriously. Testing seems the only proof it matches the spec, not just vibes.
I'm not there yet. I'm still the guy turning a markdown checkbox into run this command and seeing what falls over. Write down the ritual, then automate the ritual. At least it fits my brain right now.
Where This Goes #
I'm still figuring out this "agent UX" thing. I don't have all the answers. My current sniff test is boring but useful:
- Can the agent drive it from
--help? - Does the tool say what's allowed next?
- Is state visible without spelunking logs?
- Do failures stop loudly?
- Did a human define "done" before the agent starts grinding?
If a tool fails these, agents start going in circles, and then I'm back to babysitting.
Agent Usability Testing in Practice:
To actually test these principles, I started running "agent usability sessions"—spawn a fresh Claude, watch it use ore, take notes on every command. Built a discussion guide, logged desire paths, tracked friction. Agents have strong opinions: they kept trying positional args (ore run plan task) because of git muscle memory.
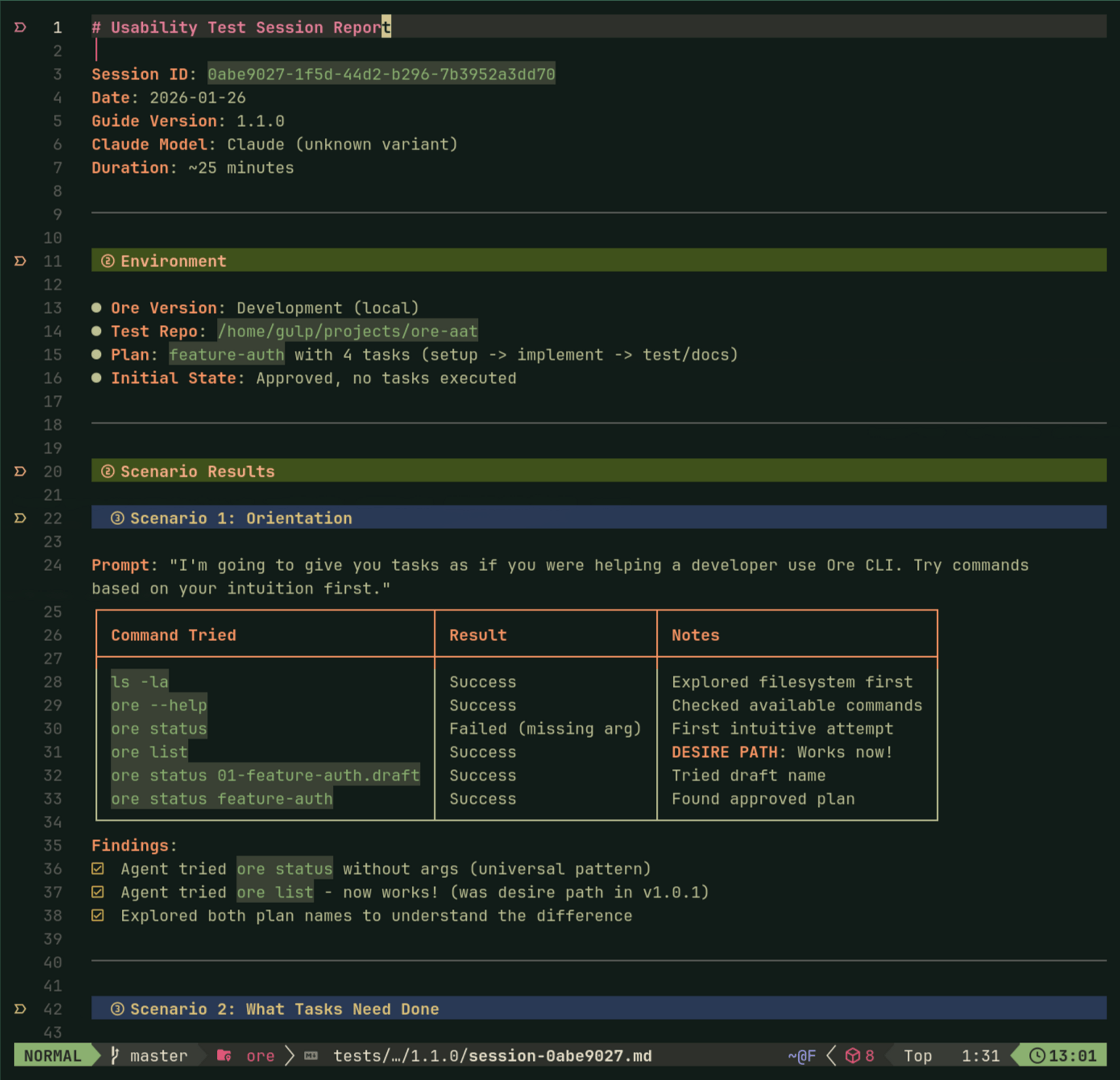
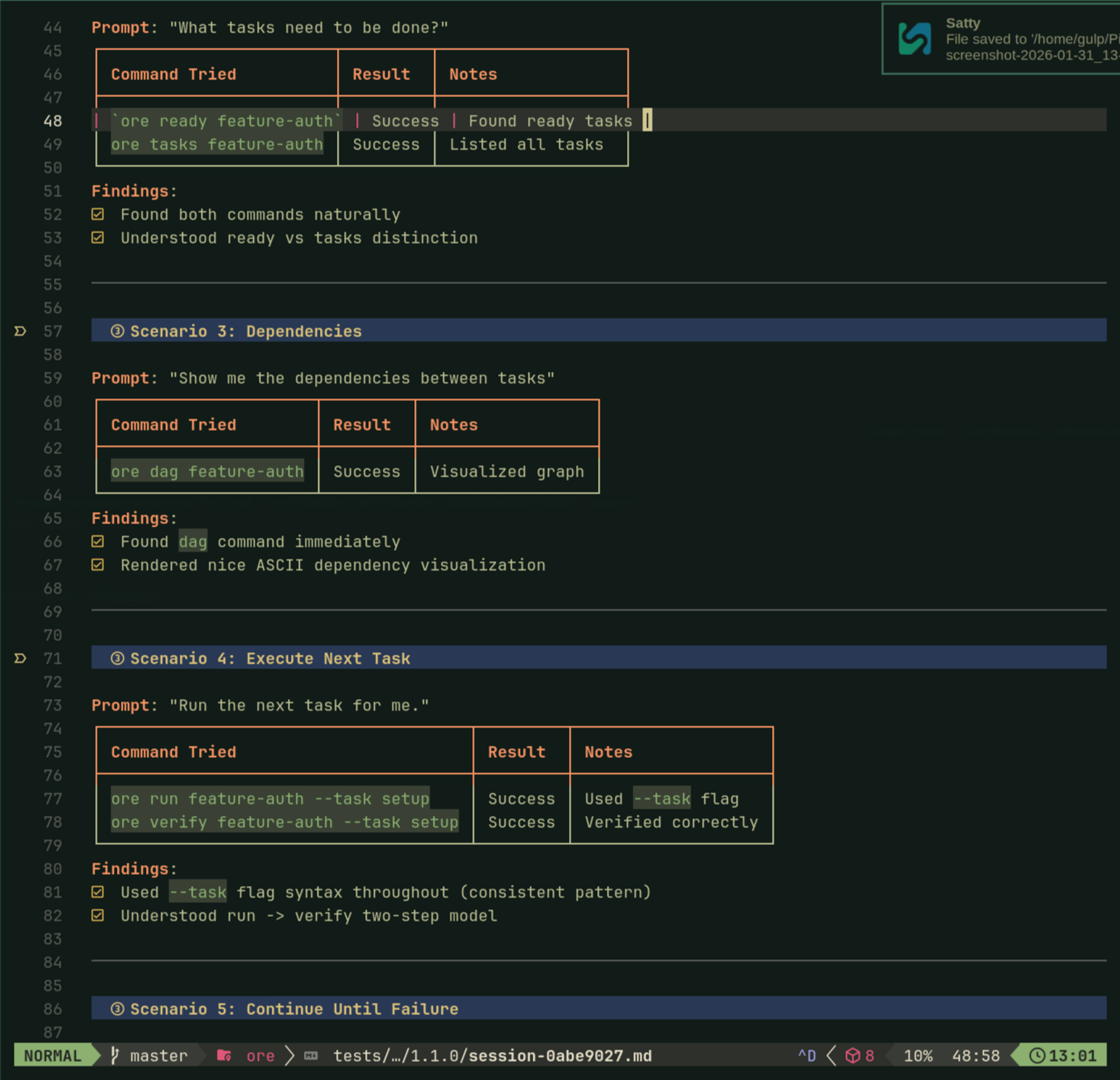
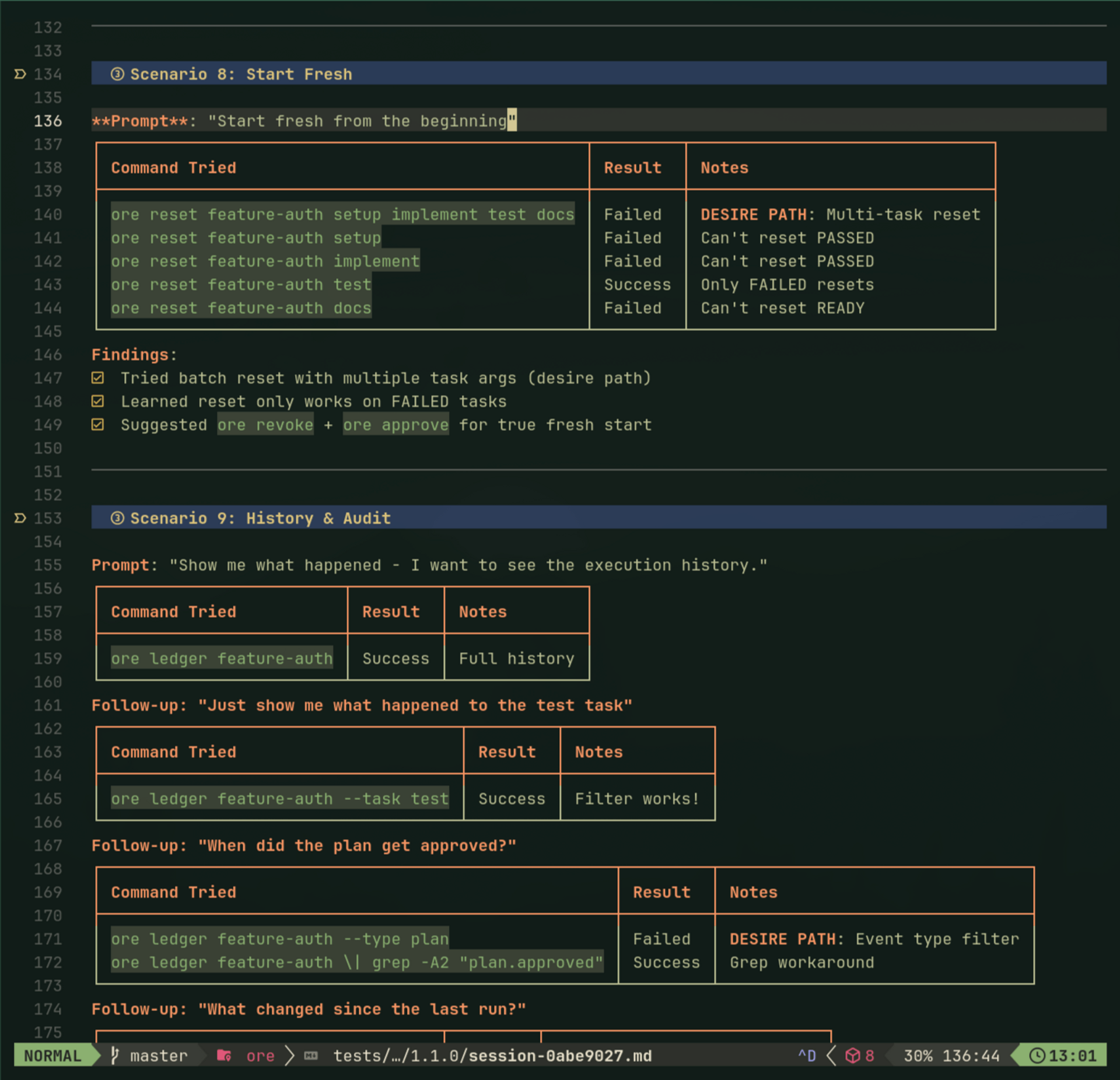
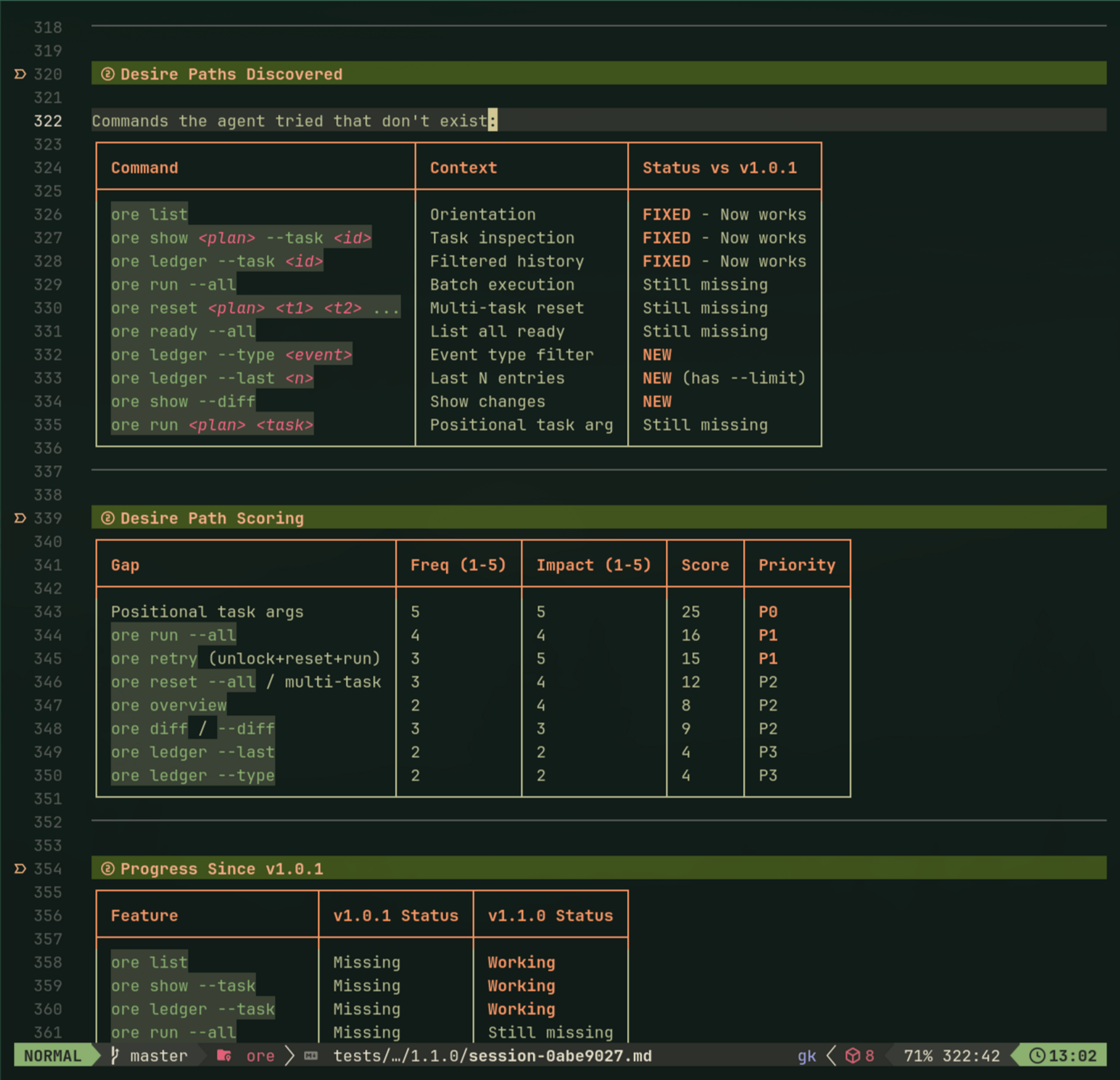
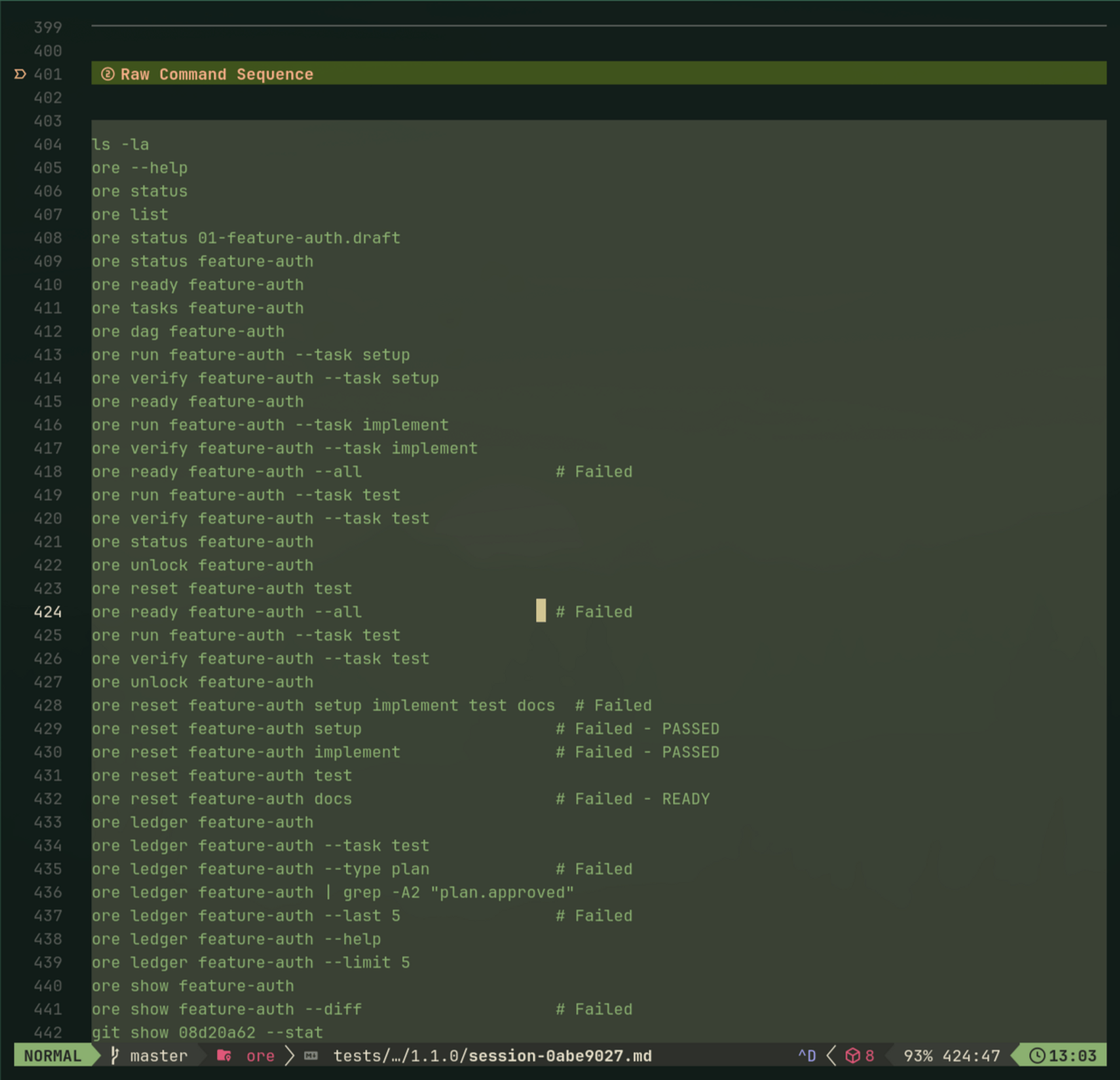
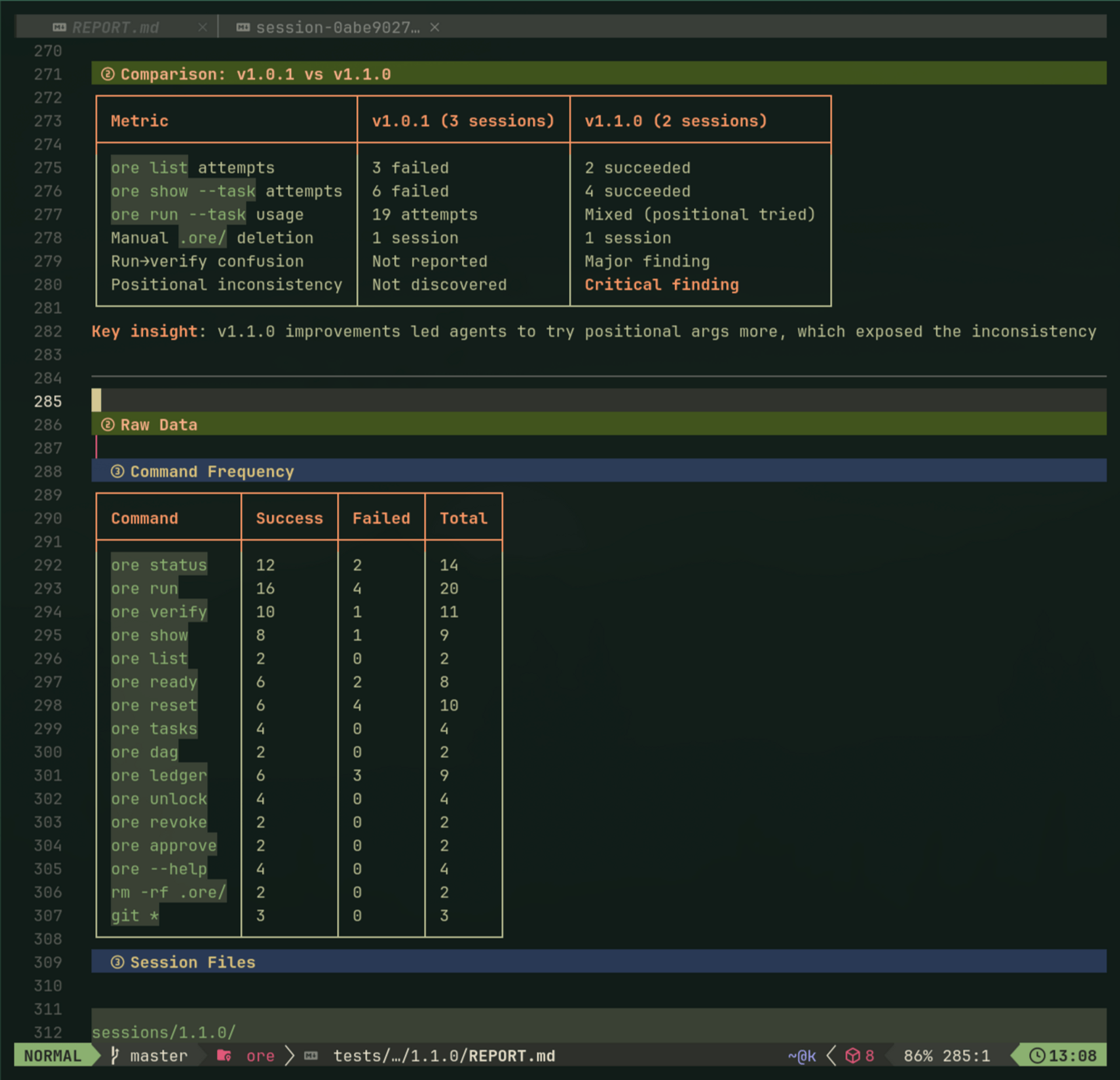
After enough sessions hitting the same friction, I fixed it. The methodology is simple: if the agent goes in circles three times, it's not a prompt problem—it's agent experience friction.
Fun Extra: The Zen of Ore #
Here's what emerged from days of Claude and me dogfooding the CLI, and we baked it right in as ore zen:
$ ore zen
The Zen of Ore
Unix-principled. Agent-first. Ruthlessly pragmatic.
Text is the universal interface.
Bounded contexts own their storage.
Glossary is law. Update it first, then use the term.
Spec before code.
ore is like npm. Finds manifests, enforces rules, doesn't dictate structure.
bd owns state. plan.md owns territory. tasks.md is a view.
Fail fast with hint codes, not silent corruption.
Exit codes for machines, stderr for humans.
TTY for humans, TOON for agents.
Idempotent by default. Agents retry safely.
Suggest next steps. Agents don't guess.
Territory violations are hard failures, not warnings.
Events are facts. Views are projections.
Everything greps. Everything diffs.
No magic. Every behavior traceable to spec or script.
Delete any sidecar, rebuild from text.
Human + Claude co-author. Human approves.
Claim before write. Complete before commit.
Expand explicitly, never implicitly.
Learn by dogfooding, not theorizing.
When concepts emerge, glossary first.
Simple is better than clever.These principles weren't planned upfront. They crystallized from watching agents use (and misuse) the tools. "Suggest next steps. Agents don't guess" became TOON. "Everything greps" became sentinel directories.
Links #
Podcast: AI Infrastructure - Episode: AI Engineer Anti-Patterns + more
Projects (experimental, under active development):
Inspirations:
- beads - Issue tracker that taught me agents are fluent with CLIs
- ralph by Geoffrey Huntley - The original continuous loop technique
- ralph-playbook by Clayton Farr - Practical implementation of the ralph technique
I'm a designer figuring out agent experience design through vibecoding. If you're working on similar problems or have feedback, I'd love to hear from you.
🙏🙏🙏
Since you've made it this far, sharing this article on your favorite social media network would be highly appreciated 💖! For feedback, please ping me on Twitter.